Text Extractor for Mac is an easy-to-use OCR application. With advanced OCR function provided by Text Extractor for Mac, you can quickly extract text content out of your scanned paper document and images file, convert them into editable and searchable text content.
For the best OCR extraction results, please read this detailed instruction.
1. Launch the app and open a file
Open Finder > Applications and click on ‘Text Extractor’ icon. When the interface shows up, click ‘OPEN FILE’ button. Then you can select a file that you wish to perform extraction from the slide-down finder window.
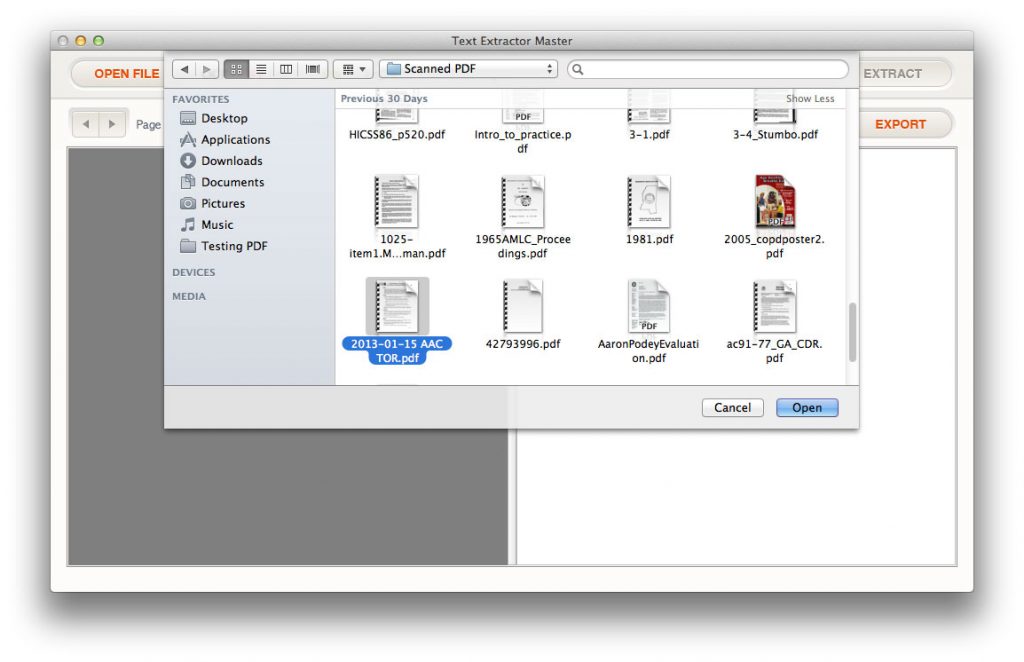
Supported input file formats:
PDF Document (.pdf)
Image formats: png, jpeg, jpg, tif, tiff, bmp, gif.
2. Select output and OCR options
If the imported file is not a scanned file or image, you don’t need to enable the OCR option and select document language.
If you import image file or scanned PDF file, please enable OCR, select the correct document language.
Tips: How to distinguish scanned PDF file from normal file>>
You can select convert all pages or current page.
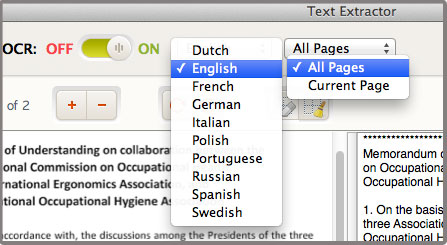
3. Start extraction
Click the ‘Extract’ button, the conversion will begin.
4. Use the extracted text content
When the extraction process is finished, you’ll see text content are available in the output area. You can edit the content directly within the output area, copy text content into the clipboard, or extract it as plain text file (.txt).
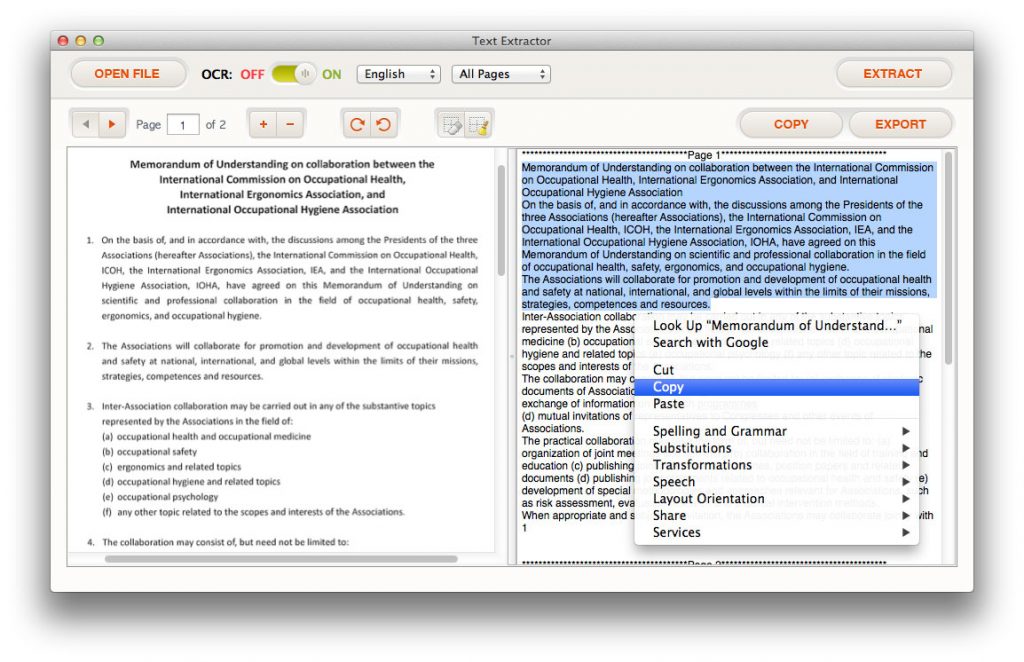
Advanced steps for increasing the conversion quality and your productivity:
1. Improve conversion quality
(1) Increase image resolution
The accuracy of OCR conversion depends on the quality of the original PDF. Poor document images quality and a skewed document may not be recognized accurately.
The image should be at least 300 dpi, and 600 dpi is recommended for document with smaller fonts. Or the text will be stuck together and OCR is hard to accurately recognize those text.
OCR can do a better job for documents with white background and black text content.
(2) Rotate page to the correct orientation
The PDF document or image must be right-side up.
(3) Select correct document language
Selecting the correct document language is very important, for example, if your PDF file is in Russian, but you choose English as a recognition language, the result will not correct.
(4) Point out the picture area
If you don’t want to extract text from picture areas or any particular areas of the imported file, please drag to point out those areas.
2. Run spelling check to quick fix incorrect recognition
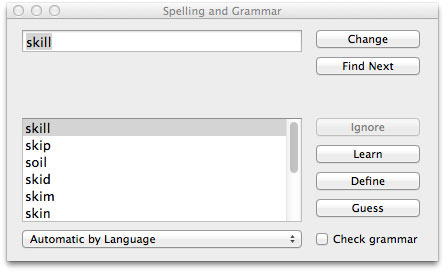
OCR is not an easy task, some similar characters, for example, ‘e’ and ‘c’, ‘l’, ‘i’ and ‘!’ may not be recognized correctly. Running a spelling check can quickly locate those mistakes and correct them quickly.
Right-click on the output area, choose ‘Spelling and Grammar’ -> ‘Show Spelling and Grammar’.
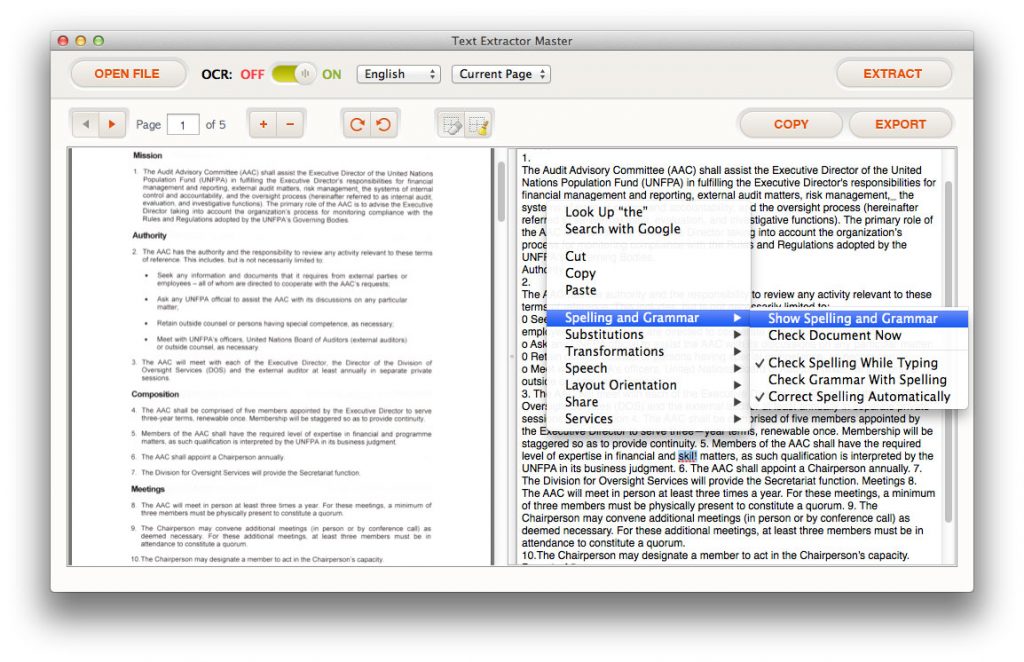
A window will pop up. For example, ‘skill’ is mistakenly recognized as ‘Skil!’, run the spelling checker to quickly discover this mistake, select the right one from the recommendation and click the ‘Change’ button.
You may also interested in the following product:
PDF to Word OCR for Mac – Convert electronic and scanned PDF files into editable and well-formatted Microsoft Word document.